“Probability theory is nothing but common sense reduced to calculation.” — Pierre-Simon Laplace, 1814
“When you have uncertainty, and you always have uncertainty,” Judea Pearl said, “rules aren’t enough.” Pearl had arrived at AI by accident. Semiconductors wiped out his job at a memory research lab in 1969, he called a friend at UCLA, and took whatever position was available.
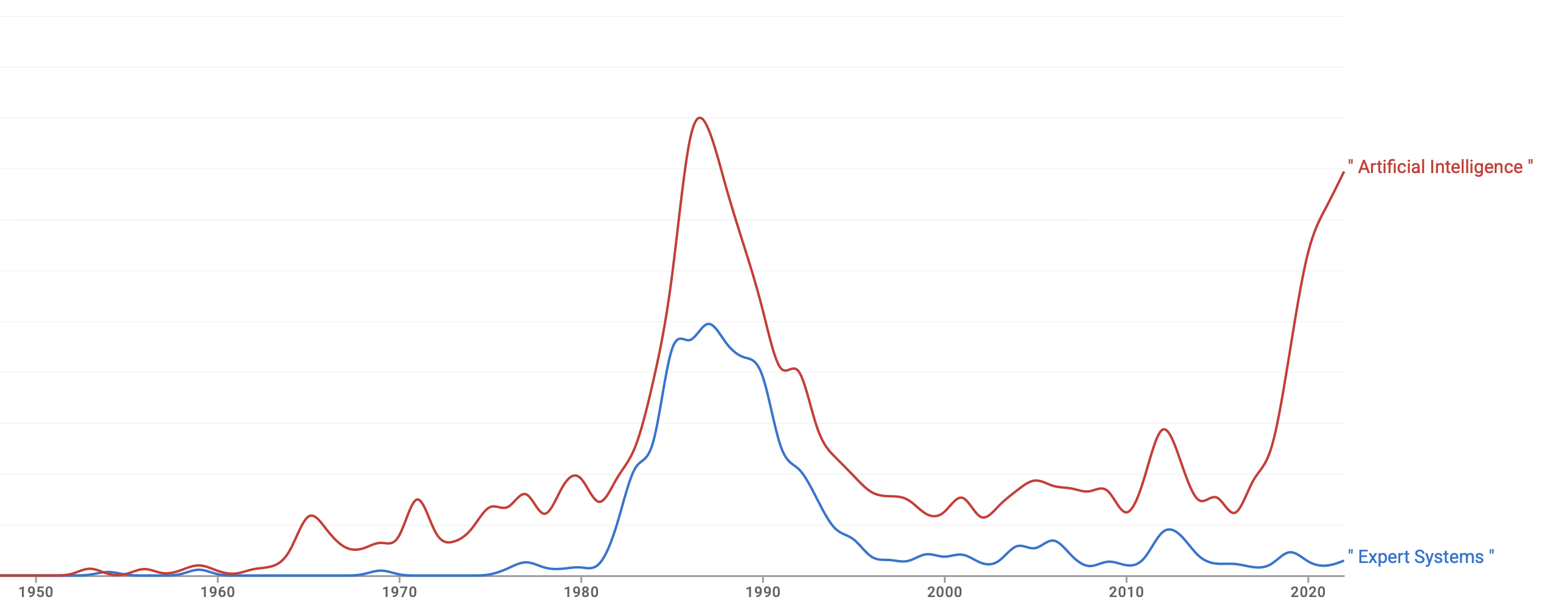
He spent years reading the field’s approaches to uncertain reasoning — fuzzy logic, belief functions, certainty factors — and became convinced it was avoiding something it already had the mathematics for. Bayes’ theorem had been available since 1763. It told you exactly how to update a belief when evidence arrived. Why was nobody using it?
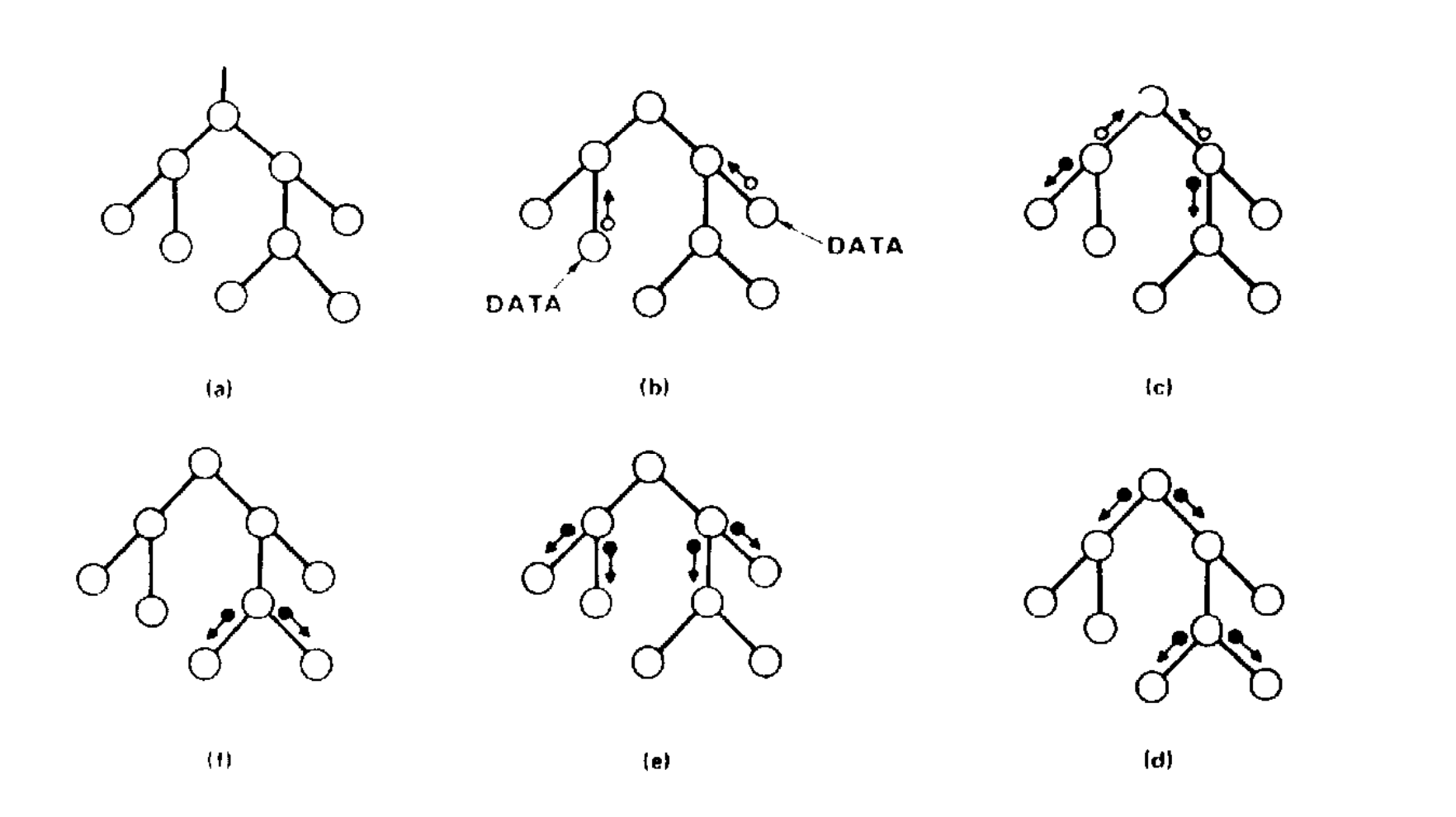
The answer he arrived at was Bayesian networks: a graph where each node is a variable and each edge represents how one variable influences another. A disease node connects to symptom nodes, each connection carrying a probability table derived from data. When evidence arrives, it propagates through the graph and the mathematics tells you the most probable explanation.
The idea came from cognitive science. He had been reading a 1976 paper by David Rumelhart on how children read, which showed how neurons at multiple levels pass messages back and forth to resolve ambiguity, for example whether a smudged word is “FAR” or “CAR” or “FAT.” Pearl realised these messages had to be conditional probabilities. Bayesian reasoning was essential for passing them up and down the network and combining them correctly.
David Heckerman at Stanford built PATHFINDER using Pearl’s framework, a system for diagnosing lymph-node diseases across 60 conditions and 130 symptoms. Get the diagnosis wrong and a patient could miss life-saving treatment. Experienced specialists frequently disagreed with each other on exactly these calls. PATHFINDER matched the accuracy of the leading expert whose knowledge it had been built from.
But Bayesian networks only answered one kind of question: given what I observe, what is most probable? Pearl called this the first rung of a ladder, and spent the next decade climbing it.
-
Seeing. What is the probability of X given I observe Y? This is what Bayesian networks do, and what all statistics does. You watch a thousand smokers and note how many get cancer.
-
Doing. What would happen if I intervened and set X to a particular value? Observational data cannot answer this, however much of it you have. Watching smokers tells you nothing about whether making someone stop smoking will reduce their cancer risk, which is why Pearl formalised do-calculus to handle it.
-
Imagining. What would have happened if things had been different? The patient died. Would they have survived with a different drug? No dataset contains the answer to a counterfactual. Pearl developed the mathematics to reason about it anyway.
Pearl argued they were fundamentally different kinds of question, and that conflating them had caused enormous confusion in science, medicine, and economics for over a century.
Pearl received the Turing Award in 2011 for the first revolution. By then he was deep into the second, and later wrote that “fighting for the acceptance of Bayesian networks in AI was a picnic compared with the fight I had to wage for causal diagrams.”
Further Reading
-
Pearl, J. (1982). “Reverend Bayes on Inference Engines: A Distributed Hierarchical Approach.” AAAI-82 Proceedings.
-
Heckerman, D., Horvitz, E., & Nathwani, B. (1992). “Toward Normative Expert Systems: The Pathfinder Project.” Methods of Information in Medicine.
-
Pearl, J. (2018). “Theoretical Impediments to Machine Learning with Seven Sparks from the Causal Revolution.” arXiv.
-
Pearl, J. (2018). “A Personal Journey into Bayesian Networks.” UCLA Cognitive Systems Laboratory.
-
Pearl, J. (2023). “Judea Pearl, AI, and Causality: What Role Do Statisticians Play?” Amstat News.